Em 2012, o mundo voltou sua atenção para Genebra, na Suíça, quando o CERN (Organização Europeia para a Pesquisa Nuclear) anunciou que encontrou uma partícula com características consistentes com o Bóson de Higgs. Na mídia, e para descontentamento de muitos cientistas, a partícula foi apelidada de “partícula de Deus”, por representar a chave para explicar a origem da massa de outras partículas elementares.
Recebida com empolgação por parte da comunidade científica, a descoberta do Bóson de Higgs reiterou a robustez do Modelo Padrão de partículas, considerada uma das teorias mais bem sucedidas da física, que descreve como as estruturas que compõem o universo são formadas por meio da interação entre 17 partículas elementares. O reconhecimento mundial veio em outubro 2013, quando os físicos François Englert e Peter Higgs foram laureados com o Nobel de Física, “pela descoberta teórica do mecanismo que contribui para a compreensão da origem da massa das partículas subatômicas, cuja existência foi recentemente confirmada ao ser descoberta a partícula fundamental pelos experimentos ATLAS e CMS do Grande Colisor de Hádrons do CERN”.
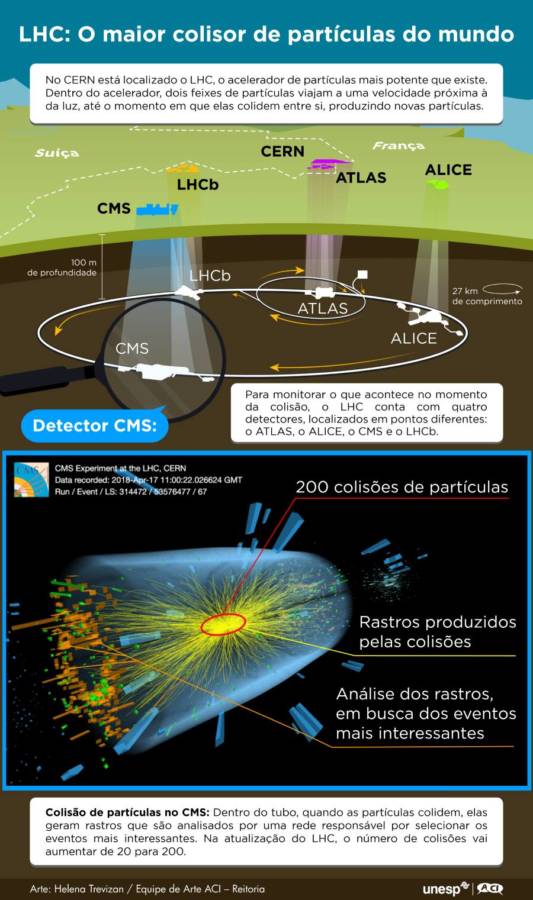
Como destacado pela Academia Real das Ciências da Suécia, o avanço foi possível graças ao Grande Colisor de Hádrons (LHC) que, até hoje, é reconhecido como o maior e mais potente acelerador de partículas do mundo. O LHC consiste em um túnel subterrâneo circular, de 27 km de comprimento, no qual feixes de partículas são lançados e viajam a velocidades enormes até colidirem entre si. Na colisão, as partículas reagem produzindo novas partículas as quais, após a colisão, viajam através dos experimentos. O resultado da colisão é, então, monitorado por quatro detectores: ATLAS e CMS, sendo os dois maiores, e ALICE e LHCb. Os dados obtidos são analisados por cientistas do mundo inteiro que buscam por novas partículas e por explicações para alguns dos maiores mistérios da física, como a composição da matéria escura.
No Núcleo de Computação Científica da Unesp, localizado no campus Barra Funda, uma equipe de professores, pesquisadores e técnicos colabora com o desenvolvimento e armazenamento de dados do Compact Muon Solenoid (CMS), um dos experimentos do LHC responsável por identificar o Bóson de Higgs. As ações são desenvolvidas pelo SPRACE, Centro de Pesquisa e Análise de São Paulo, criado em 2003 com apoio da Fapesp.
Além de processar, analisar e armazenar os dados gerados pelo CMS, a equipe também trabalha com instrumentação científica, desenvolvendo novos eletrônicos que serão implementados na atualização do LHC, prevista para acontecer em 2027. “Nós trabalhamos com a eletrônica chamada back-end. A eletrônica de front-end encontra-se localizada no detector e é responsável pela medição das partículas, já a back-end é a responsável por conduzir o processamento dos dados”, comenta Luigi Calligaris, pesquisador do SPRACE encarregado de coordenar os projetos relacionados ao desenvolvimento de hardwares e códigos para o CMS financiados pela Fapesp.
Atualizando o maior colisor de partículas do mundo
O CMS funciona como uma câmera gigante de alta velocidade que tira “fotografias” 3D de colisões entre partículas. Trata-se de um gigantesco desafio, inclusive pelo número de eventos assim que podem ocorrer: até 40 milhões de colisões por segundo. Devido à quantidade de dados que esses registros geram, é impossível que algum ser humano possa olhar para eles a fim de determinar quais são interessantes ou não. Na colisão de partículas, o foco das pesquisas está naqueles eventos que resultam na produção de partículas de média ou alta energia. Entretanto, estas são as ocorrências mais raras; o mais comum é que se verifiquem processos que ensejam partículas de baixa energia, e que não são de interesse dos pesquisadores.
Por conta disso, cada detector do LHC conta com uma rede responsável por selecionar os eventos mais interessantes, composta por diferentes processadores chamados “triggers”. A rede analisa as informações recebidas e decide quais eventos merecem atenção. Ao final do processamento apenas 1 a cada 40 mil eventos é salvo. E esse número ainda vai aumentar. Estima-se que, com a atualização do LHC, a quantidade de partículas colidindo em cada evento suba de 20 para 200, elevando as chances de novas descobertas. Luigi Calligaris, que também é pesquisador do NCC-Unesp, comenta que, para lidar com o aumento de colisões, foi necessário projetar uma modificação do trigger de primeiro nível, que é o estágio inicial, aquele que “faz uma seleção grossa” dos eventos, para aumentar sua sensibilidade. “Os processos raros que produzem partículas de alta energia são geralmente fáceis de identificar, mas os processos raros que produzem partículas de média energia podem ser frequentemente confundidos com os processos triviais, de pouco interesse”, explica o pesquisador.
Assim, apesar de o aumento de colisões elevar as chances de produção de eventos interessantes, há o risco de que estes fiquem “diluídos” e desapercebidos em meio a grande quantidade de processos pouco interessantes, que também serão produzidos. A atualização do trigger inicial, portanto, visa evitar que partículas de média energia passem despercebidas. “Para resolver isso, vamos adicionar a informação dos rastros dos processos raros ao algoritmo do trigger inicial, porque eles têm características geométricas diferentes dos processos triviais; isso permitirá distinguir com mais eficiência os eventos interessantes”, completa Calligaris.
Mas essa opção acarreta alguns problemas. Devido à necessidade de processar uma quantidade muito maior de informação no mesmo período de tempo, o algoritmo responsável pelo primeiro estágio do trigger não pode rodar em softwares, porque os programas não seriam capazes de alcançar a velocidade de processamento necessária. Para contornar essa situação, o algoritmo irá rodar diretamente em placas programáveis, chamadas de FPGA.
Ao contrário da maioria dos chips pré-programados que encontramos rotineiramente em televisões, celulares, rádios, etc., as placas FPGA são completamente programáveis. Isso permite que o usuário, por meio de diferentes combinações de circuitos e funções, defina qual será a funcionalidade da placa, permitindo que sejam feitas alterações ou até reformulações completas de suas funções. É possível pensar nas placas como um jogo de lego, no qual cada combinação de peças e cores permite um resultado diferente. “Essa flexibilidade das FPGAs tem muitas vantagens para a evolução do experimento, da testagem e do desenvolvimento dos algoritmos, porque nem todos os aspectos do detector estão completamente estabelecidos”, afirma Calligaris.
Metodologia de acesso aberto
No SPRACE, Calligaris lidera o projeto Fapesp que está buscando a melhor maneira de configurar as placas para que executem as funções necessárias no CMS. Uma vez configuradas, essas placas irão compor o back-end do tracker do CMS, parte responsável por gravar os rastros que as partículas deixam após a colisão e que contém informações cruciais sobre o que ocorreu no centro da colisão. Além do hardware, o grupo de pesquisa também está desenvolvendo um equipamento responsável por analisar a saúde das placas utilizadas em todo o detector.
Calligaris diz que somente a construção do tracker irá demandar o uso de 500 placas FPGA. Outros sub-detectores usados no experimento, assim como outros componentes, também irão depender de grande quantidade de placas e, além das que estarão em uso, deverão ser produzidas placas de reserva, para o caso de que alguma venha a falhar ou a quebrar. “Um ser humano não pode olhar 500 páginas de gráficos de análise todo o tempo para checar a saúde das placas. É preciso um sistema automático que faça isso e que tome a decisão de desligá-las se ficarem em condições perigosas”, explica o pesquisador. “As FPGAs são caras. As que nós vamos usar custam vários milhares de dólares cada, então é melhor que não queimem”, brinca.
As placas ficarão hospedadas em uma caverna subterrânea adjacente à caverna principal, onde está localizado o experimento CMS, em equipamentos conhecidos como shelves ATCA (Arquitetura de Computação de Telecomunicações Avançada, em português). Essa infraestrutura permite a gestão e o monitoramento constante das placas. Porém, para que isso seja possível, cada uma das placas FPGA deve contar com um dispositivo conhecido como Intelligent Platform Management Controller (Controlador de Gerenciamento de Plataforma Inteligente) ou IPMC.
O IPMC é responsável por medir regularmente valores operacionais das placas, como as temperaturas, as tensões e as correntes. A partir da interação com os shelves, é feita a decisão de ligar ou desligar as placas, baseado nas medidas reportadas. “Essa infraestrutura de gestão do hardware (HPM) permite operar o back-end com altíssima confiabilidade, baixa taxa de acidentes e pouco tempo perdido devido a falhas ao longo da operação do experimento”, diz Calligaris. Esses recursos também permitem ter uma visão completa de todo o sistema e investigar o motivo de possíveis falhas.

Ao longo dos anos houve várias tentativas de desenvolver IPMCs aptas para o uso nos experimentos de física, porém muitas tinham restrições. Algumas foram bem sucedidas apenas com placas específicas, enquanto outras foram desenvolvidas junto a empresas privadas, o que gerou problemas de licença e limitações sobre sua utilização. Assim, o grupo de pesquisa composto por integrantes do SPRACE desenvolveu o projeto OpenIPMC, um código aberto de IPMC, junto a uma placa (OpenIPMC-HW), também com projeto aberto, capaz de rodar esse código. “Desenvolvemos um sistema de acesso aberto, que permite ao desenvolvedor de placas ATCA trabalhar com um IPMC totalmente configurável, conforme as necessidades do seu usuário”, explica o pesquisador.
O projeto teve início a partir de uma colaboração com o Instituto de Processamento de Dados (IPE) do Karlsruhe Institute of Technology – KIT (Alemanha) e com o grupo de pesquisa do professor Ailton Akira Shinoda, da Faculdade de Engenharia da Unesp, campus Ilha Solteira. “A placa está sendo usada pelo CERN, por pesquisadores do Imperial College, em Londres, na Boston University, na Cornell University e, além disso, o KIT está estudando a possibilidade de usá-la em um outro experimento completamente separado do CMS. Acho que isso indica que nossa ideia foi boa e aponta para a importância do investimento da academia brasileira em projetos de tecnologia aberta, que pode ser utilizada em múltiplas aplicações”, diz Calligaris.
Foto acima: o detector CMS. Crédito: Divulgação/CERN